


High SAT score in middle school does not filter for general intelligence above 2.6 SD
Estimating Yud's general intelligence and debunking a common misconception that the SMPY and clones filtered for "180 IQ"

It is a common misconception that Curtis Yarvin and Eliezer Yudkowsky are “190 IQ” because they had high SAT scores in middle school.

Here is an example. This person says Yud and Yarvin are 165 IQ because Yarvin was in the SMPY (scored over a 630 on the SATV when he was 12) and Yud did this:

In other words, he scored a 740 on the SATM and a 670 on the SATV, which was the second best combined score out of 28,000 test takers.
This is assumed to make him 170 IQ because of the place of his score among the sample, and adjustments correcting for the sample probably having an above average IQ.
The problem with this is not only the magical correction for representativeness, on top of this, the SAT is not a perfect measure of general intelligence.
No test is a perfect measure of general intelligence. But the SAT is not even designed to be a good one. It certainly is g loaded, but its g loading is not 1. Turning an SAT score directly into an estimate of general intelligence assumes that the SAT has a g loading of 1.
In fact, even using a point-estimate for general intelligence is naive. In reality, the WAIS has a reliability of about 0.80. That means even a WAIS score is in fact a random variable which can be modeled as a function of a theoretically static general intelligence, and some random noise.

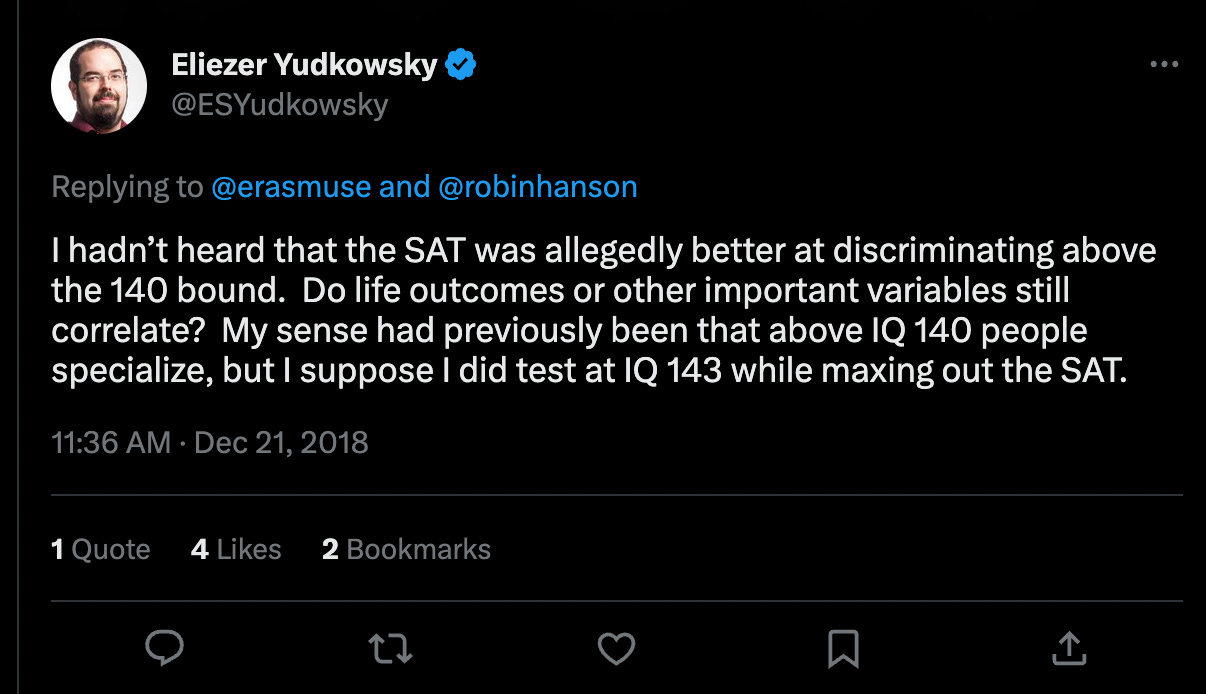
This causes “regression to the mean”. Higher FSIQ scores map onto lower g scores in Bayesian analysis. The expected value of general intelligence for someone with a 3SD WAIS score (145 FSIQ) is only 2.4 SD (136).
You can see from the chart above that there is a lot of variance of general intelligence given a WAIS FSIQ score. What this means is that using a point estimate of E[g | FSIQ] does not mean much. It is better to do Bayesian updating and change our prior distribution given a new data point. The distribution will converge strongly on a value as more data is considered. Good estimates of general intelligence should be holistic, not SAC’d. SACing refers to ignoring the totality of the evidence in exchange for 1 piece of preferred evidence which is interpreted under uncritical priors. It stands for stubborn assumption cherrypicking. In this case, people SAC on Yud and Yarvin’s IQ by latching on to one piece of evidence (their middle school SAT scores) under the priors that those scores are perfectly g loaded.
Knowing these things, we estimate Yudkowsky’s general intelligence.
Generally, what we have are a bunch of scores, which each imply some probability distribution for his general intelligence. We just want to perform MLE on these scores.
If we just had a bunch of WAIS scores:
So if it were just a bunch of WAIS scores we want:
This is just a standard mean MLE inference problem. However, if we incorporate scores from different tests, the variance can change. Nonetheless, if we know the variance for the distribution of test scores given g for each test, we can just use that variance for that datapoint. Depending on what test some x_i (observed score) came from, there will be a different variance for its distribution on general intelligence. We are still dealing with essentially the same problem. In fact, we only have three scores to perform inference on.
There was his 143 WAIS score, and we have estimate that the correlation between general intelligence and WAIS score is 0.80 from reliability estimates. There was also his middle school SAT score, and a 1600 in high school.

We will charitably let his middle school SAT score be 4.66 SD. As discussed, it is invalid to then estimate is general intelligence to be 4.66 SD. We need to know how g loaded his test was. We can estimate this by using the g loading of the 1990s SAT in general. We will charitably ignore things like demonstrable IQ obsession which might make over-scoring on tests more likely.
As for the 1600 score, there were 500 of those scores that year, and about 1.7 million test takers. This makes that score about 1/3400, or about 3.5 SD.
For these tests, we will use Seb Jensen’s figures. For the age 15 SAT score, the correlation between the score and adult general intelligence should be about 0.80. For the middle school score, because of variance due to developmental pace, we apply yet another regression of 0.82 to reflect the correlation between childhood g given chronological age, and adult general intelligence.
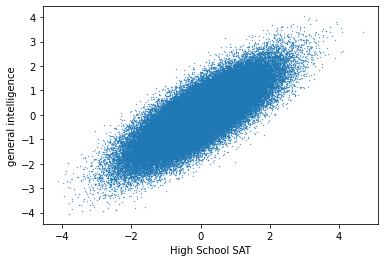

We want to know this:
Using Python, we can just plot this product as a function of g. The maximum is Yud’s most likely general intelligence.
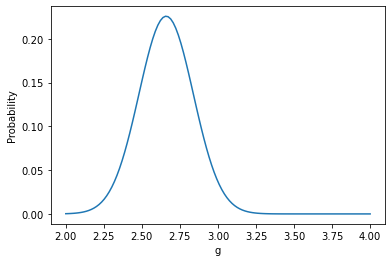
Yud’s most likely g, given charitable assumptions and only his testing data, is about 2.6 or 139 IQ. He almost certainly is not over 145 and almost certainly is not under 130.
Now you see what the SMPY and other “talent programs” that relied on middle school SAT scores do not actually find “165 IQ” people. Stop saying Yud and Yarvin are “165 IQ.”
Edit: Seb Jen said that the WAIS reliability is more like 0.92. This makes sense, the more reliable and g loaded it is, the stronger evidence it is, and the more his IQ converges on his WAIS score. The problem with the SMPY is that the SAT is just not very g loaded, and relative g at 11 is not 1:1 with relative g in adulthood. The worse the g loading of a test, the more astronomical a score needs to be to distinguish. If a g loading is only .5, you need to find someone who is 6 SD (1/millions) at that metric to claim that their expected g is 145.
Repeating the analysis with the WAIS as stronger evidence, we get this:

About 140.
Edit2:
We computed the maximum likelihood estimate, which Bayesians know as P(D|H). If we want a posterior, P(H|D), we can just use Bayes’ Theorem: P(H|D) = P(D|H)P(H)/P(D). We know P(H)! It’s just the distribution of IQs. P(D) is just the sum of P(D|H)P(H) for every g.

This is the probability distribution P(g|scores). Its argmax is 2.63 compared to the likelihood’s argmax of 2.67, which makes sense because lower IQ scores are more likely in general, and this is what that incorporates.
Reliability of FSIQ typically around .90-.95 depending on the measure. https://arthurjensen.net/wp-content/uploads/2020/04/Bias-in-Mental-Testing-Arthur-R.-Jensen.pdf chapter 7. However, this reliability is mostly concentrated among the average person. You see, when you use a fixed length test, the scores are more reliable around the mean as most items have difficulties near 0. Scores further from the mean are less reliable, and thus show much more regression. I don't know what the information figure looks like for WAIS, but a typical result is like this: https://www.researchgate.net/publication/320132198_Item_Response_Theory_for_Medical_Educationists/figures?lo=1 figure 3.
The second issue is that stability of intelligence is lower from childhood to adulthood, and of course, the achievement tests have a true g loading of .80. So SMPY and various gifted problems are not that predictive of later life intelligence as one would think. Early screening for giftedness is not that important.
I did some SAT math here but these are for regular test takers, not early test takers. Current max SAT corresponds to about 135 IQ. https://emilkirkegaard.dk/en/2022/04/iqs-by-university-degrees/
This a great post. Perfect length. No excess tangents. Doesnt just say “existing position is gay”, rather also includes “and here is an updated more accurate position”. 10/10 would read again.