


How to compute selection pressures
Part 1 of a series on evolutionary pressures and leftism

My main theory of where leftism comes from is mutational load. Leftism is highly heritable, meaning it’s very susceptible to evolutionary pressures (i.e., changes in the gene pool that produce changes in the trait). Evolutionary pressures include selection pressure, basically measured by the extent to which the average parent differs from the average person, weighted by number of offspring, times the heritability of a trait. It also includes mutational pressure, which is the amount of change in a trait de novo mutations cause in each generation. It can also include genetic drift and gene flow, but in this article we’ll just focus on mutational and selection pressure. Genetic drift essentially goes away in large populations, such as a group of 350 million people, and human race mixing tends to be low so when considering white people it’s relatively fair to just assume negligible gene flow into the group of white people.
Selection pressure
Computing selection pressure is relatively straight forward. In general, you need the following information:
How many kids people are having
What the traits are of those people
The heritability of the traits
For example, you might have a data set where you measure the number of kids everyone has and their IQ. You then find the mean IQ weighted by number of kids. By the breeder’s equation, you multiply this by the narrow-sense heritability of the trait.
Let’s break this down. The mean IQ weighted by the number of kids people has just gives the average parental-IQ of the next generation.

You can see that the above formula will work, if, say, you have 5 parent-couples with 7, 3, 1, 12, and 9 kids, and mean IQs of 100, 110, 94, 130, and 81. The result of the weighted IQ mean by fertility is the same as just taking the average parental IQ of the offspring. There are 7 offspring with parental IQs of 100, 3 with 110, and so on.
But how do we predict child IQ from parental IQ?

The correlation between the average parental IQ and their offspring’s IQ is just the narrow-sense heritability of IQ h^2.
This is because the square root of the heritability is the correlation between breeding value (hypothetically perfect additive gene score) and phenotype (thus the square of this square root is how much variance gene score explains of phenotype). Expected offspring gene value is indeed the mean parental gene value. The expected mean parental gene value is h*(mean parental phenotype). But the expected offspring phenotype is again h*(gene value).
Thus, you get expected offspring phenotype given mean parental phenotype = h*(h* (mean parental phenotype)) = h^2 (mean parental phenotype).

This gives us the equation above. It will equal the selection effect on trait g. If fertility doesn’t differ by g, it will be 0, meaning no change in the mean. If the equation equals, say, 0.2 (where g is standardized), it means the next generation will be 0.2 SDs above the current mean genetically, giving a selection pressure of 0.2 SDs.
Computing from correlations between traits and fertility
The equation we derived for computing selection pressures requires full access to a dataset there the rows are parents and the columns are number of offspring and mean phenotype. This is impractical for computing selection pressures from existing literatures, as often what is reported is a correlation between fertility and a trait. Luckily, if we know the mean and standard deviation of fertility, we can compute the selection pressure from an r value like this.

First let f(g) be the expected fertility given the standardized trait. If we know the correlation between the trait and fertility, then we simply multiply the standardized trait by the correlation and then convert the fertility SD onto the correct scale.
Now, the selection effect is the following:

I will give a proof. Say there are only two discrete values for mean parental g, -1 and 1, and you have the average fertility of each. f(-1) = 1 and f(1) = 2. Then the mean g of the next generation is just:

Which is h^2 (-1 + 2) / 3 = h^2 (1/3). This checks out. We may not have a full dataset of parents, but we know the average parent weighted by offspring is still 1/3 SD.
But this assumes g is uniformly distributed. Half of the parents are g = -1 and the other half are g = 1. What if only .25 are g = 1 and .75 are g = -1?
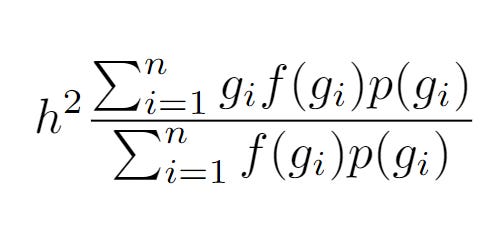
Then the next generation has a mean g of h^2 (-1*.75 +2*.25)/(1*.75 + 2*.25) = h^2 (-.25)/(1.25) = -.25.
Just convert this formula to continuous g and you have the formula with the integrals, since integrals are just continuous sums (i.e., we expand g not only be -1 and 1, but also every number in between, and we have f(g) to compute the mean fertility at any given g, and then we add all of that up).
From my own data, I have that the mean fertility of parents is 2.35 and the SD is 1.35.
In the next article, we will compute some selection pressures using r values and these numbers. Subscribe to not miss out.
Edit:
While driving I thought of a way to simplify the integral, can’t believe I missed this originally.

This should be an exciting series to read.
Joseph, as an aside, are you at all familiar with r/K selection theory? I recall around 2016 that was one of the more popular theories explaining the liberal/conservative divide.
As it pertains to this work I had a few questions, which I'm sure you'll already be answering in the next parts, but I wanted to get them out of the way:
Are there confounding factors like socioeconomic status, religion, or education level that could influence both fertility and political views independently?
How might modern environmental and social factors interact with any underlying genetic influences on political views today?
What is the mechanism by which subtle selection pressures could skew the population at a genetic level over hundreds of generations?
What other evolutionary pressures like genetic drift or migration might influence changes in political ideology over long time periods?
How testable is this overall theory? What kind of complex modeling or new data would be needed to fully evaluate it for future generations?
This has been great for keeping me fresh on mathematic concepts and practical implementation.