


Why are the psychologists BLUPing?
Best case scenario with BLUP is it melts your computer for no reason

I stumbled across this paper today as I’m getting back into thinking about social power. The topic itself I won’t discuss here, rather I’d like to make a comment on the methodology used. This is the main result:

Fine result, what sticks out to me is they used “Bayesian multilevel models.” This means BLUP, as they don’t have a prior. I love Bayesian when there’s an informed prior, but when there’s not, we have this thing called OLS. It stands for “Ordinary Least Squares” and it has this nice property — when you have no prior, its estimation of dummy variable effects on continuous outcomes is unbiased and best.
What unbiased means is that means is that if you repeat an experiment a huge number of times at any sample size, the average effect estimate result will be the true effect. Best means it does this with minimal variance. Any other estimator has more variance.
BLUP falsely claimed to be “best” and “unbiased” but it not best (there are conditions in which it has more variance than OLS), and it is not unbiased ( if you repeat an experiment a huge number of times at any sample size, the average estimate will not be the true effect).
Luckily BLUP is being renamed to “Bayesian multilevel model” which is clearer than “linear mixed model” as mixed model doesn’t mean anything unless you mean to say some of your variables are biased while some are not, so you have a mixture of biased and unbiased. But in literature on mixed models this is not clearly stated, instead they same some are “random” and some are “fixed.” Statistics redpill goggles: fixed means unbiased and random means biased.
Now why the devil would someone want to use random effects if they are biased? Well, false advertising aside, BLUP was invented to circumvent the p > n issue. This means you have more columns than rows in your data, or more features than data points. This means the matrix is singular and there is no unique OLS solution. BLUP is bad because of Garbage In, Garbage Out. It’s best use case is when the data is garbage, so it outputs garbage, but for some people that garbage is better than nothing. And sure, it’s probably better in some circumstances, like when you only care about how much variance the whole model explains.
But often you can find papers that use BLUP where they could have just used OLS. They have an invertible data matrix! If this is the case, and if the data is independent, as it often is in binary dummy variable cases, I have a formula for BLUP’s bias.
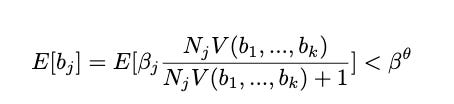
Setting the variance to 1, it’s applies shrinkage to each parameter of about n/n+1 on average. So if n is 10, the reported effects are only 90% of the true effects, on average. If n is 1000, BLUP effects are on average 99.9% as large as OLS effects. So BLUP is asymptotically unbiased when the data is nice, at least. But when the data is nice, there’s no point in using it.
What was nice about the article I mentioned is that the data is totally open source, as it should be. So I downloaded the R code and ran the model. It took 800 seconds (13 minutes) to compute, because BLUP uses gradient descent — it’s actually a form of ridge regression that is optimized.
Meanwhile OLS computes almost instantly.
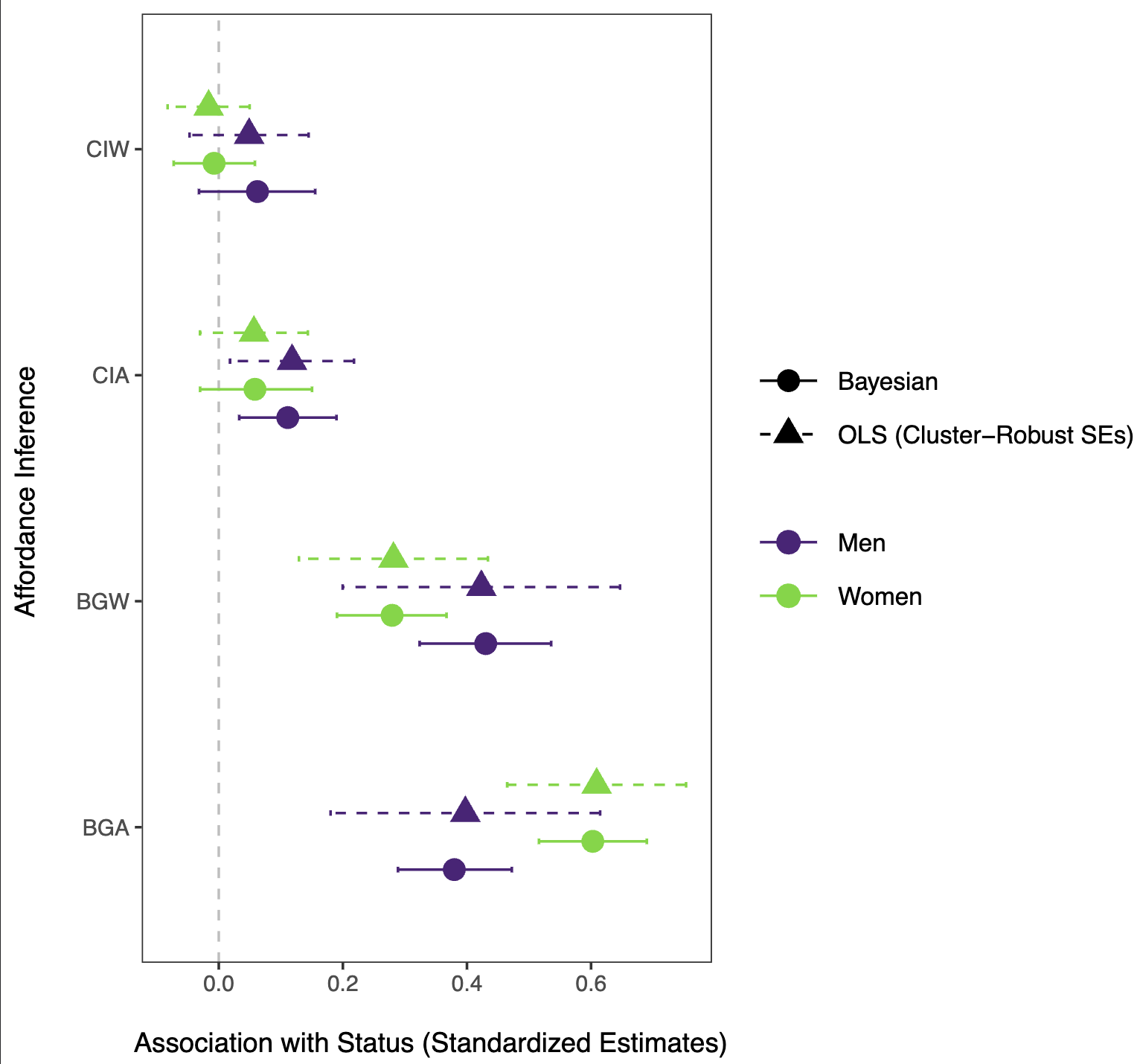
It gives basically the same result, using the appropriate cluster SEs. But this is easier on your computer and is theoretically more robust, because you know your estimates are unbiased. So why not use OLS?
The sci-hub link to the paper does not work